Syntaxus baccata
Syntaxus baccata
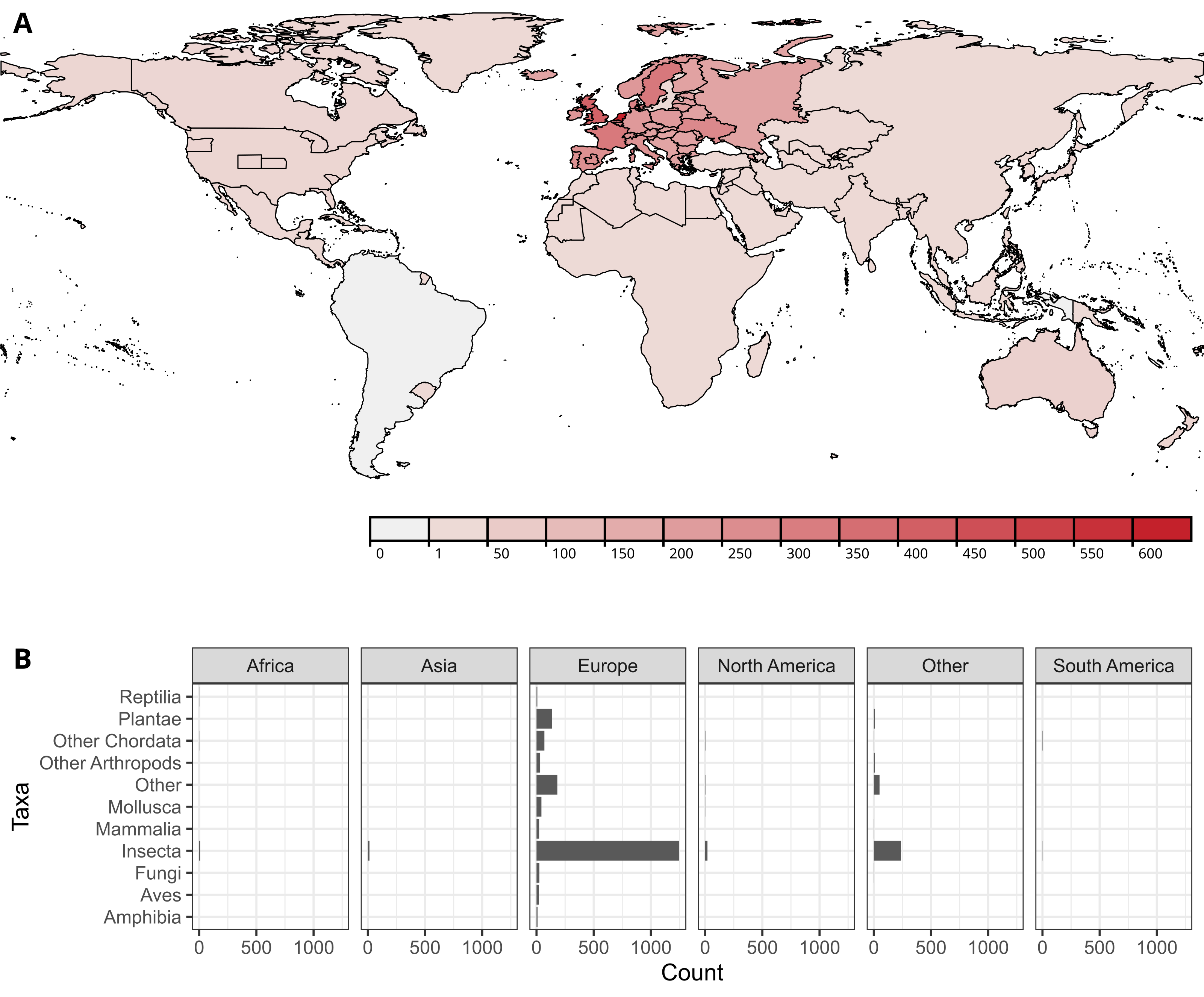
The Library of Identification Resources (LoIR) is a database of identification keys and other publications and resources that assist in the taxonomic identification of animals, plants, and fungi. As a result, the database contains a lot of taxonomic info, which can be roughly divided into two parts. Firstly, the taxonomic scope of every identification key or other type of resource is recorded, like “hoverflies” or “Syrphidae” in a key to the hoverflies of Europe. Secondly, if feasible, checklists are made for all of the individual species (or genera, etc.) included in each of the identification keys. Both sets of scientific names of taxa are mapped to external databases to allow easier comparisons and, importantly, to power the search engine. Until two days ago, this external database was the GBIF Backbone Taxonomy, maintained by the Global Biodiversity Information Facility (GBIF).
However, in June of 2026, GBIF replaced the GBIF Backbone Taxonomy with the Catalogue of Life (COL). This comes with many improvements, as the Catalogue of Life gets frequent updates, includes taxa with intermediate ranks, and provides an Extended Release (COL XR). The COL XR integrates additional checklists leading to better coverage of less common taxa, obscure synonyms, and recent taxonomic changes, directly affecting the data quality of GBIF. As opposed to the GBIF Backbone Taxonomy, which used to integrate various datasets as well, there also seems to be a clear path for small data publishers like LoIR to contribute to the COL XR.
This change also means that LoIR needed to move from the GBIF Backbone Taxonomy to COL (XR) before GBIF fully deprecates the old system. This transition came with its own challenges, for both parts of the taxonomic data in LoIR. Back in 2025, we found that the base release of COL missed 14.3% of the ‘endpoint’ taxa in checklists of identification keys in LoIR, compared to just 3.5% by the GBIF Backbone Taxonomy (Willighagen & Jongejans, 2025). The pressing question for me was whether COL XR could improve on this enough to use it as the main taxonomy in LoIR.
Now, after updating the tools used to develop LoIR (see Willighagen, 2026), all identification checklists have been mapped to COL XR instead of COL. This lead to a marked improvement, leaving just 3.5% of endpoint taxa unmapped compared to 5.0% with the GBIF Backbone Taxonomy. Only 1,029 scientific names (0.9%) were mapped to the GBIF Backbone Taxonomy but could not be mapped to COL XR (Fig. 1). This is a good sign!
Note that since 2025, the overall mapping coverage of both COL and the GBIF Backbone Taxonomy decreased, due to the addition of many publications about Heteroptera published between 1880 and 1963. Looking only at checklists added before August 4th, 2025 (see Willighagen, 2025), COL XR misses only 2.4% of endpoint taxa, compared to 3.5% with the GBIF Backbone Taxonomy at the time.

Figure 1: Alluvial diagram of changes in the coverage of mappings of endpoint taxa in checklists between the GBIF Backbone Taxonomy and COL XR.
The other part of the taxonomic info in LoIR, the taxonomic scopes, was more difficult to convert. However, here COL (XR) also offers immense improvements by including taxa with intermediate ranks. For example, say an identification key is intended for all weevils, i.e. the superfamily Curculionoidea. Before, that taxonomic scope had to be mapped to all constituent families, because the GBIF Backbone Taxonomy did not include superfamilies or any other intermediate taxa. Now, it can simply be mapped directly to COL’s entry for Curculionoidea: KV7G2.
This was possible for most, but not all taxa. For example, the subfamilies of shield bugs (Pentatomidae) have not been added to COL (XR) yet, and therefore still had to be mapped to all genera separately. The list of taxonomic scopes also contain a lot of taxa that are now considered obsolete, and have to be mapped to multiple current taxa. However, whereas with the GBIF Backbone Taxonomy only 72.5% of taxonomic scopes could be mapped directly, with COL XR this raises to 90.2% (Fig. 2). Additionally, 23 taxa that were not mapped at all in the GBIF Backbone Taxonomy are now mapped to COL (XR). Unfortunately, there were still 5 taxa that could not be mapped to COL (XR) yet, mostly heteropteran genera.
COL XR as a whole does still require some additional curation. An issue with COL’s name index meant there are a lot of duplicate entries for the same taxa in the current release of COL XR (26.6). Additionally, some genera have been given an incorrect classification (see the previous link), and as aforementioned, several species, genera, and higher taxa are still missing. This should all improve as COL XR continues to develop though, and now hopefully the data in LoIR could contribute to this!

Figure 2: Alluvial diagram of changes in the coverage of mappings of taxonomic scopes between the GBIF Backbone Taxonomy and COL XR.
After both sets of taxonomic info in LoIR were adapted to use COL XR, the search engine had to be updated to use the new mappings. This process was relatively simple, as GBIF has API endpoints for both the GBIF Backbone Taxonomy and COL XR. The API endpoint for COL XR is technically still experimental, but an equivalent, stable version will likely be added in the future.
All in all, I think this is a great succes, and I am excited for future developments.
References
- Willighagen, L. (2025). Library of Identification Resources Catalog (Versions 2025-08-04) [Dataset]. Zenodo. https://doi.org/10.5281/zenodo.16738485
- Willighagen, L. G., & Jongejans, E. (2025). Library of Identification Resources: A FAIR overview of taxonomic keys. Biodiversity Data Journal, 13, e161726. https://doi.org/10.3897/BDJ.13.e161726
- Willighagen, L. (2026). identification-resources/formica: v0.10.1 (Version v0.10.1) [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.8208214